
Настройка отказоустойчивого кластера OpenNebula
Настройка High Available кластера на базе OpenNebula
Данная статья является продолжением серии предыдущих постов.
Я буду использовать pacemaker, corosync и crmsh.
Отключим автозапуск демонов OpenNebula на всех серверах
1 | systemctl disable opennebula opennebula-sunstone opennebula-novnc |
Добавим ha-clustering репозиторий
/etc/yum.repos.d/network:ha-clustering:Stable.repo
1 | [network_ha-clustering_Stable] |
Установим необходимые пакеты
1 | yum install corosync pacemaker crmsh resource-agents -y |
Если конфликтуют пакеты при установке resource-agents, установим дополнительно:
1 | sudo yum install cifs-utils psmisc lvm2 |
На основном сервере KVM-1, редактируем файл corosync.conf и приводим его к следующему виду:
1 | totem { |
Генерируем ключи:
1 | cd /etc/corosync |
Копируем конфигурационные файлы на другие сервера кластера:
1 | scp /etc/corosync/{corosync.conf,authkey} oneadmin@KVM-2:/etc/corosync |
Запускаем сервисы:
1 | sudo systemctl start pacemaker corosync |
Если сервис стартует с ошибкой:
1 | -- Unit corosync.service has begun starting up. |
Выполняем даунгрейд sudo yum downgrade corosync corosynclib
Проверяем статус работы:
1 | sudo crm status |
1 | Last updated: Fri Apr 8 13:25:09 2016 Last change: Fri Apr 8 13:24:50 2016 by hacluster via crmd on KVM-2 |
Отключим STONITH (механизм добивания неисправной ноды)
(В конце статьи присутствует ссылка на материал об этом).
1 | crm configure property stonith-enabled=false |
Если в работе используется только два сервера, необходимо отключить кворум, чтобы избежать splitbrain ситуации.
1 | crm configure property no-quorum-policy=stop |
Создаем ресурсы:
1 | crm |
В данном случае мы создали виртуальный адрес 192.168.2.111, добавили три сервиса OpenNebula в кластер и объеденили их в группу Opennebula_HA.
Проверяем состояние:
1 | sudo crm status |
1 | Last updated: Fri Apr 8 13:32:44 2016 Last change: Fri Apr 8 13:32:10 2016 by root via cibadmin on KVM-1 |
Настройка OpenNebula
На данном этапе необходимо добавить ноды, хранилище и виртуальные сети в наш кластер.
Веб-интерфейс Sunstone будет доступен по адресу http://192.168.2.111:9869:
- Создаем кластер;
- Добавляем ноды;
Если в процессе добавления хостов появится ошибка, то исправляем её повторной установкой /usr/share/one/install_gems, либо запускаем onehost sync --force.
1 | Fri Apr 8 13:40:47 2016 : Error monitoring Host H1-KVM-1 (0): |
Все ноды должны быть активны:
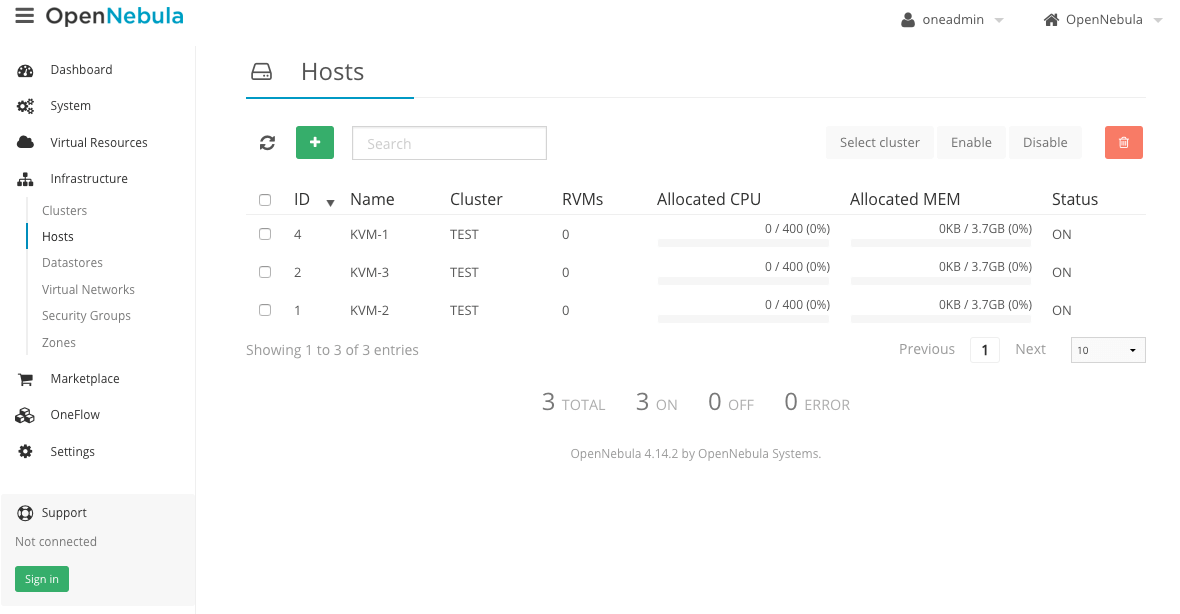
- Добавляем виртуальную сеть:
1 | cat << EOT > ovs.net |
1 | onevnet create ovs.net |
- Добавляем Ceph хранилище:
4.1) На Frontend ноде (KVM-ADMIN) создаем Ceph пользователя для работы с OpenNebula хостами. В данном примере имя пользователя client.libvirt (само имя пользователя libvirt, префикс client указывает на пользователя в Ceph).
4.2) Создаем пользователя с полными правами rwx для пула TEST:
1 | ceph auth get-or-create client.libvirt mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=TEST' |
4.3) Генерируем ключи:
1 | ceph auth get-key client.libvirt | tee client.libvirt.key |
4.4) Теперь нам необходимо скопировать все файлы ключей на OpenNebula хосты.
ceph.client.libvirt.keyringдолжен быть размещен в директории/etc/ceph(на всех серверах в том числе и frontend).client.libvirt.keyможет быть размещен в любом месте, где пользовательoneadminимеет привилегии доступа и сможет создать секретные ключи libvirt.
1 | for i in 2 3; do |
1 | for i in 2 3; do |
4.5) Генериреум UUID конмадой uuidgen, полученное значение будет далее использоваться как $UUID.
1 | [ceph@KVM-ADMIN ~]$ uuidgen |
4.6) Создаем файл secret.xml
$UUID меняем на полученное значение из предыдущего пункта;
1 | <secret ephemeral='no' private='no'> |
Копируем файл secret.xml между всеми KVM нодами OpenNebula.
4.7) Следующие команды должны быть выполнены на всех KVM нодах от пользователя oneadmin в директории с файлами secret.xml и client.libvirt.key.
Например:
1 | [oneadmin@KVM-2 ~]$ virsh -c qemu:///system secret-define secret.xml |
1 | [oneadmin@KVM-2 ~]$ virsh -c qemu:///system secret-set-value --secret $UUID --base64 $(cat client.libvirt.key) |
Проверить установленные значения можно следующей командой:
1 | [oneadmin@KVM-2 ~]$ sudo virsh secret-list |
В завершении добавляем Ceph хранилище в OpenNebula
1 | cat << EOT > rbd.conf |
1 | onedatastore create rbd.conf |
Также можно добавить Ceph в качестве системного хранилища.
1 | NAME = "CephSystem" |
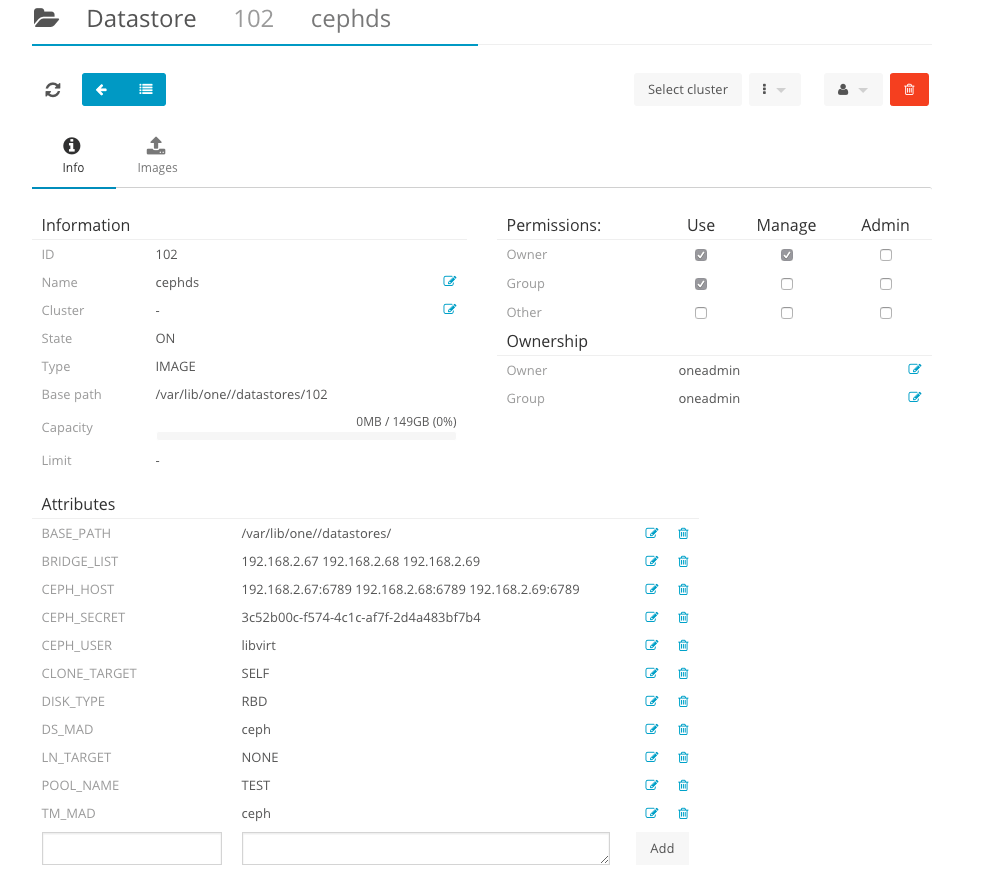
Внимание! Данные действия будут работать только при условии активной cephx авторизации.
Драйвер Ceph работает нормально только с KVM.
По умолчанию используется формат RBD 2, пропишем данный параметр в конфигурационном файле ceph.conf
1 | [global] |
Обновим конфигурацию на всех серверах:
1 | ceph-deploy config push {host-name [host-name]...} |
HA для виртуальных машин
Для настройки High Availability для виртуальных машин, следуем официальной документации OpenNebula
1 | HOST_HOOK = [ |
Аргументы:-m - миграция виртуального сервера на другой хост. Только для хостов в одном хранилище.-r - удаление и пересоздание виртуального сервера. Все данные будут утеряны.-d - удаление виртуального сервера с хоста.-p <n> - избегать повторного представления хоста, если хост возвращается в строй после N-циклов мониторинга.
В версии 5.2 добавлен функционал fencing.
Читать на docs.opennebula.org
Скопируем конфигурационный файл на другие ноды кластера:
1 | for i in 2 3; do |
Troubleshooting
Если появляется ошибка вида:
1 | Error copying image in the datastore: Error registering images/one-3 |
То исправляем её установкой или обновлением пакета ceph-devel.
Список испольуземых материалов: